
Generative AI, often referred to as deep learning models, stands at the forefront of technology, crafting high-quality content such as text and images based on the data on which it’s trained.
You might already be acquainted with the acronym GPT, which stands for Generative Pre-trained Transformer. It’s rooted in LLM (Large Language Model), a sophisticated computer algorithm that processes natural language inputs and predicts subsequent words based on learned patterns.
To delve into the intricate working of these models, let’s explore tokens – the basic units of text or code that LLMs use to process and generate language. These tokens, whether characters, parts of words, or entire sentences, are assigned numerical values and compiled into vectors, constituting the actual input for the first neural network of the LLM. For further insights, refer to our previous article about this topic: https://parserdigital.com/unleashing-the-power-of-generative-ai-understanding-transformers/.
While there are many generative AI tools available, concerns regarding data privacy have prompted our team to explore the option of having complete control over our data. This drive led us to develop our own LLM, enabling us to harness the benefits of Generative AI without compromising the security and confidentiality of our organisation’s information.
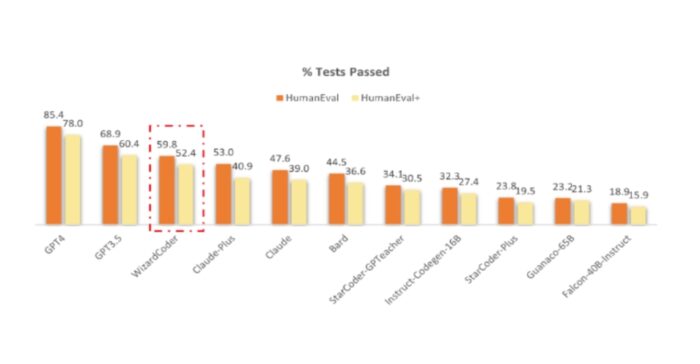
Opting for efficiency, we downloaded a pre-trained model from HuggingFace WizardCoder 15B quantised using AutoGPTQ algorithm. This model showcased better results compared to others, as illustrated in the chart below:
We deployed our model on a AWS EC2 G5 instance, using the g5.xlarge instance type, incurring a monthly cost of approximately $160. To ensure a seamless connection between our model and various client applications, we developed a set of APIs in Python and connected them with custom Slackbots, Jira, and Visual Studio Code plugins. We achieved excellent performance, operating with 250-400 tokens and an average response time of 10 seconds.
Certainly, this approach wasn’t without its challenges. The provisioning of an EC2 instance required meticulous configuration and setup to ensure compatibility with the machine learning model. This involved installing dependencies, CUDA libraries, and building APIs to facilitate seamless integration. Nevertheless, with the right security configurations, we maintained control over our data.
Why not use AWS Sagemaker Jumpstart?
With SageMaker infrastructure, you can provision resources for training a new model from scratch or choose from a variety of pre-built models available through Jumpstart, including those from HuggingFace. SageMaker also provides the flexibility to refine compatible models. While offering enhanced control over your ML projects, it does demands additional setup. It’s important to note that endpoint usage comes with associated charges. If you shut down a notebook on an instance without closing the instance, you’ll still incur charges. Additionally, shutting down Studio notebooks won’t delete supplementary resources created with Studio, such as SageMaker endpoints, Amazon EMR clusters, and Amazon S3 buckets. Therefore, exercising caution when using SageMaker is essential to avoid unexpected costs.
Our cost comparison between LLM on Amazon EC2 and Amazon SageMaker, revealed nearly identical expenses, with no significant differences. Although setting up SageMaker Jumpstart was easier and faster, it requires careful management to prevent unnecessary costs. In contrast, using the LLM on EC2 is just as simple as stopping and restarting the instance, making it an equally convenient option with more control over costs and flexibility.
So, what happens with BedRock?
Amazon BedRock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI 21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon. This service comes with a single API, along with a broad set of capabilities needed to build generative AI applications, simplifying development while maintaining privacy and security.
It provides three distinct pricing models:
- On-Demand
- Provisioned Throughput
- Model customisation (fine-tuning)
In this article, we delve deeper into the On-Demand model, where essentially AWS provides an API to consume different models without the need to provision any infrastructure. Charges are incurred solely based on demand for requests and the quantity of tokens used. AWS consistently expands its collection, currently boasting approximately ten different models.
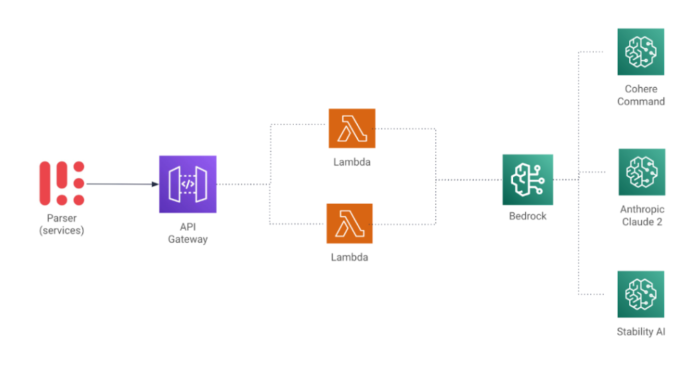
In our quest to minimise cloud costs, we opted for a serverless API. We went ahead and created a simple Rest API using API Gateway and Lambda functions to consume BedRock and test the different models.
We created a lambda function with the boto3 client,

and by just transforming the request payload into the right prompt depending on the model and setting up the parameters,
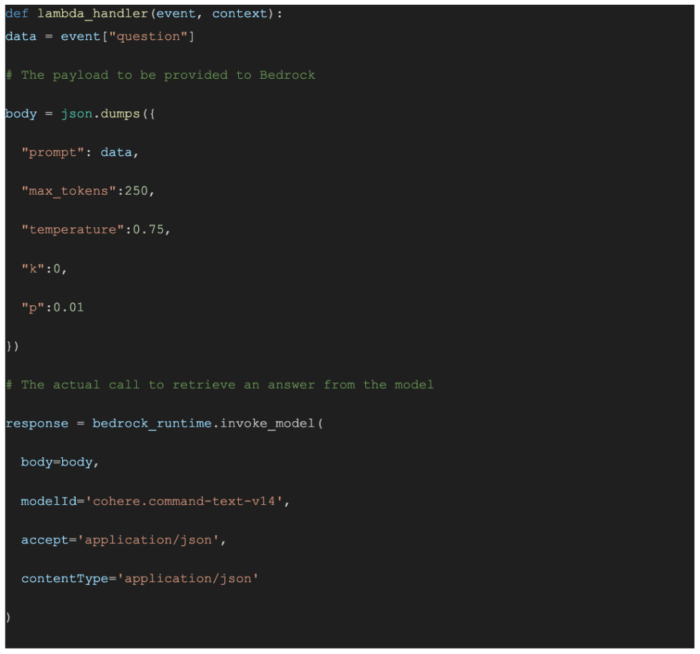
we have a ready to go serverless API to invoke BedRock.

A few considerations:
- You might need to add a Lambda layer containing the latest Boto3 dependencies to support BedRock.
- You can use InvokeModelStream for a better user experience.
- If you decide to use Lambdas, keep in mind ColdStarts.
Now, let’s delve into the details of performance. We observed no noticeable differences; it seems the EC2 instance replies faster in some scenarios, but the time difference is minimal.
Cost comparison
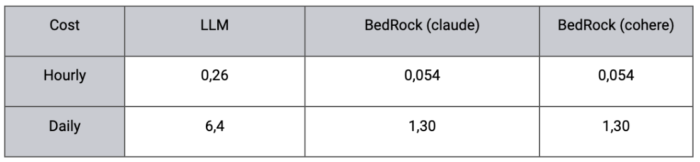
*As seen, there is no difference between the different models in BedRock, but compared with the LLM hosted on EC2, it’s significant!
Final Thoughts
If you’re seeking a solution to develop custom bots and plugins to optimise your business operations while maintaining data security and cost efficiency, BedRock is the perfect choice for you.
Stay tuned for our next post, where we’ll delve into training and provisioned throughput over BedRock.
