
Introduction
Generative Artificial Intelligence (AI) has emerged as a revolutionary force, pushing the boundaries of what machines can achieve in various fields. Among the many advancements in Generative AI, the Transformer model has gained immense popularity for its ability to generate human-like text, images, and more. In this article, we’ll delve into the workings of the Transformer model, explore the pivotal phrase “attention is all you need,” and shed light on the diverse techniques of fine-tuning that enable us to harness the true power of generative AI.
The Transformer Model: A Paradigm Shift in Language Processing
The Transformer model represents a paradigm shift in Natural Language Processing, overcoming the limitations of traditional Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). Proposed in the landmark 2017 paper “Attention is All You Need” by Vaswani et al, Transformers introduced a novel mechanism for capturing long-range dependencies within sequences without the need for sequential processing.
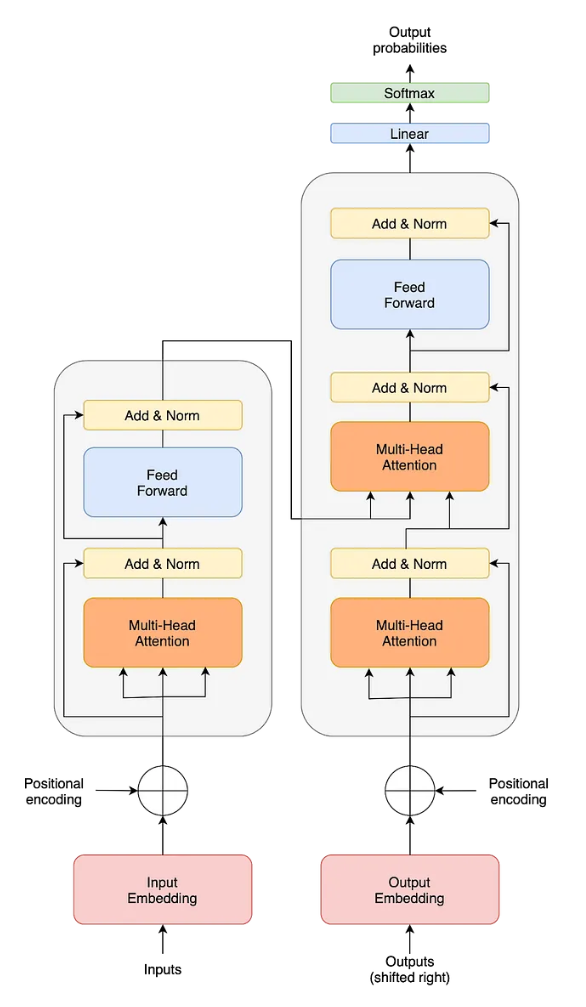
The key innovation lies in the self-attention mechanism. Instead of relying solely on the sequential flow of information, the Transformer allows each word or token in a sequence to attend to all other words simultaneously. This means that every word has access to the entire context of the sentence during processing, making it highly effective in understanding context and generating coherent and contextually relevant responses.
“Attention is All You Need”: The Revolutionary Idea
The phrase “Attention Is All You Need” encapsulates the central concept of the Transformer model. By leveraging self-attention, the Transformer fundamentally alters the manner in which AI models manage sequential data. The attention mechanism assigns weights to each word’s importance concerning the other words in the sequence. Words that are more relevant to the current context are given higher weights, allowing the model to focus on the most important information while processing the sequence.
In the context of language generation, this is immensely powerful. Instead of relying solely on the preceding words in the sequence to predict the next word, the Transformer model considers all words and assigns relevance accordingly. As a result, the model can capture complex relationships, nuances, and dependencies within sentences, leading to more accurate and coherent language generation.
Training and Fine Tuning
Training and fine-tuning are two key processes involved in preparing a transformer model for a specific task or application.
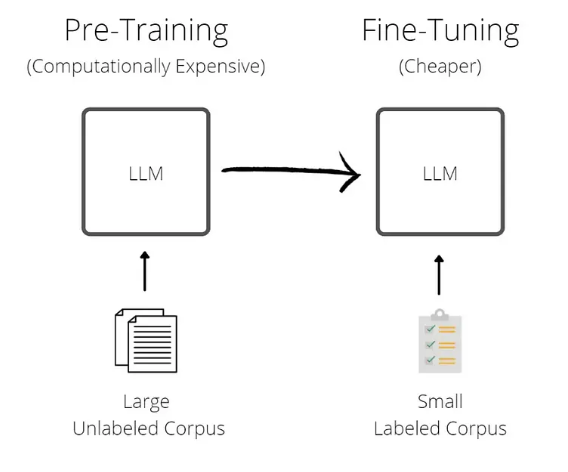
Training a Transformer Model
Training a transformer model involves training it from scratch on a large and diverse dataset. During this process, the model learns to understand language patterns, grammar, semantics, and even some level of reasoning from the data it’s exposed to. It involves optimizing the model’s parameters (weights and biases) so that it can generate coherent and contextually relevant text.
For instance, GPT-3 was trained on a massive corpus of text data from the internet, allowing it to learn grammar, facts, and world knowledge. Training involves exposing the model to input sequences and then predicting the next word in a sentence. This process is repeated for countless sentences, enabling the model to learn the underlying patterns and relationships in language.
Fine-Tuning a Transformer Model
Fine-tuning comes after the initial training and involves adapting a pre-trained model to perform a specific task or cater to a particular domain. Instead of training the model from scratch, which would require a vast amount of task-specific data, fine-tuning utilizes a smaller dataset specific to the desired task.
In the fine-tuning process, the pre-trained model’s parameters are adjusted slightly based on the task-specific data. This helps the model leverage its general language understanding while tailoring it to the nuances of the task.
Zero-shot learning, one-shot learning and few-shot learning are all techniques that allow a machine learning model to make predictions for new classes with limited labeled data.
- Zero-Shot Learning: In zero-shot learning, a model is tested on tasks it has never seen during training. The model uses its general understanding of the data and any available background knowledge to make predictions. For example, if a language model is asked to translate between language pairs it hasn’t been explicitly trained on, it can still attempt translations based on its grasp of language patterns.
- One-Shot Learning: One-shot learning involves training a model with only one example per class or task. The model is expected to generalize from this single example and perform reasonably well on new, unseen examples from the same classes or tasks. This is quite challenging and might not always lead to high accuracy.
- Few-Shot Learning: Few-shot learning is a broader concept where a model is trained with a small number of examples per class or task, typically more than one but still a small fraction of what traditional machine learning models require. The idea is to leverage this limited data to quickly adapt the model to new tasks. Few-shot learning often involves meta-learning or other techniques that help models generalize better from small datasets.
Additional techniques related to these concepts include:
- Meta-Learning (Learning to Learn): Meta-learning involves training a model to learn the learning process itself. It is used in few-shot learning scenarios, where a model is trained on multiple tasks in a way that it can quickly adapt to new, similar tasks with a limited number of examples.
- Transfer Learning: Transfer learning involves training a model on a source task and then using the knowledge gained from that task to improve performance on a target task. In the context of language models, this could involve pretraining a model on a large text corpus and then fine-tuning it on a specific task with limited labeled data.
- Data Augmentation: Data augmentation involves artificially increasing the size of the training dataset by applying various transformations to the existing data, like adding noise, rotating, cropping, or altering the data in ways that preserve its meaning. This can help the model generalize better with limited data.
- Prompt Engineering: In language tasks, creating well-crafted prompts or input formats can guide the model’s behavior. By designing prompts carefully, even few-shot or zero-shot models can generate desired responses.
- Adaptive Learning Rates: When training on small datasets, using adaptive learning rate techniques, such as learning rate scheduling or smaller initial learning rates, can help prevent overfitting and lead to better convergence.
- Regularization Techniques: Techniques like dropout, weight decay, and layer normalization can help mitigate overfitting when training on small amounts of data.
These techniques are important for overcoming the challenges posed by limited data, enabling models like LLMs to perform well in various scenarios with only a small amount of information available for training.
Effective Use Cases for Transformer Models
Transformers and Generative AI have shown significant power and versatility across a wide range of use cases due to their ability to process and generate text, which includes understanding context, capturing patterns, and producing coherent responses. Some prominent use cases include:
- Natural Language Understanding (NLU): Transformers excel at tasks like sentiment analysis, named entity recognition, intent recognition, and text classification. They can accurately understand and categorize the content of text, helping companies understand public sentiment towards their products, services, or brand by analyzing social media posts, reviews, and comments.
- Text Generation: This is one of the most prominent use cases. It’s used for content creation, creative writing, and more.
- Chatbots and Virtual Assistants: Transformers have revolutionized the field of chatbots. They can hold natural, context-rich conversations with users, understand queries, and provide relevant responses.
- Summarization: Transformers can generate concise and coherent summaries of long pieces of text, making them invaluable in applications like automatic document summarization and news article summarization.
- Question Answering: Models like BERT and T5 can read a given passage and answer questions about the content with remarkable accuracy, making them valuable for building AI systems that answer queries.
- Image Captioning: Transformers can also be used in conjunction with computer vision models to generate descriptive captions for images, enhancing accessibility and searchability.
- Text Completion: Transformers can suggest auto-completions for sentences, aiding writers in generating coherent and contextually appropriate content.
- Language Translation and Multilingual Applications: Transformers are adept at translating text between different languages, enabling effective communication across linguistic barriers.
- Code Generation: Transformers can assist in generating code snippets, providing programmers with quick and contextually relevant solutions. There are relevant Open Source pretrained models available on Hugging Face like WizardCoder for this purpose.
These are just a few examples, and the potential applications of transformers and generative AI continue to expand as researchers and developers explore new ways to harness their capabilities.
Conclusion
Generative AI, powered by the Transformer model, has ushered in a new era of natural language processing and creativity. With the revolutionary concept of “attention is all you need,” the Transformer model enables machines to understand context and generate human-like text with unprecedented accuracy and coherence. Through fine-tuning, developers can unleash the true potential of the Transformer model, adapting it to a myriad of specific tasks and applications, making it a driving force in shaping the future of AI-powered creativity and language processing.
